While 100% indexing may be possible in terms of ‘technical,’ it’s likely not going to be possible in reality.
When it comes to topics like crawl budget, the historic rhetoric has always been that it’s a problem reserved for large websites (classified by Google as 1-million-plus webpages) and medium-sized websites with high content change frequency.
In recent months, however, crawling and indexing have become more common topics on the SEO forums and in questions posed to Googlers on Twitter.
From my own anecdotal experience, websites of varying size and change frequency have since November seen greater fluctuations and report changes in Google Search Console (both crawl stats and coverage reports) than they have historically.
A number of the major coverage changes I’ve witnessed have also correlated with unconfirmed Google updates and high volatility from the SERP sensors/watchers. Given none of the websites have too much in common in terms of stack, niche or even technical issues – is this an indication that 100% indexed (for most websites) isn’t now possible, and that’s OK?
This makes sense.
Google, in their own docs, outlines that the web is expanding at a pace far outstretching its own capability and means to crawl (and index) every URL.
function getCookie(cname) {
let name = cname + “=”;
let decodedCookie = decodeURIComponent(document.cookie);
let ca = decodedCookie.split(‘;’);
for(let i = 0; i <ca.length; i++) {
let c = ca[i];
while (c.charAt(0) == ' ') {
c = c.substring(1);
}
if (c.indexOf(name) == 0) {
return c.substring(name.length, c.length);
}
}
return "";
}
document.getElementById('munchkinCookieInline').value = getCookie('_mkto_trk');
In the same documentation, Google outlines a number of factors that impact their crawl capacity, as well as crawl demand, including:
- The popularity of your URLs (and content).
- It’s staleness.
- How quickly the site responds.
- Google’s knowledge (perceived inventory) of URLs on our website.
From conversations with Google’s John Mueller on Twitter, the popularity of your URL isn’t necessarily impacted by the popularity of your brand and/or domain.
Having had first-hand experience of a major publisher not having content indexed based on its uniqueness to similar content already published online – as if it is falling below both the quality threshold and doesn’t have a high enough SERP inclusion value.
This is why, when working with all websites of a certain size or type (e.g., e-commerce), I lay down from day one that 100% indexed is not always a success metric.
Indexing tiers and shards
Google has been quite open in explaining how their indexing works.
They use tiered indexing (some content on better servers for faster access) and that they have a serving index stored across a number of data centers that essentially stores the data served in a SERP.
Oversimplifying this further:
The contents of the webpage (the HTML document) document are then tokenized and stored across shards, and the shards themselves are indexed (like a glossary) so that they can be queried quicker and easier for specific keywords (when a user searches).
A lot of the time, indexing issues are blamed on technical SEO, and if you have a noindex or issues and inconsistencies preventing Google from indexing content, then it is technical, but more often than not – it’s a value proposition issue.
Beneficial purpose and SERP inclusion value
When I talk about value proposition, I’m referring to two concepts from Google’s quality rater guidelines (QRGs), these being:
- Beneficial purpose
- Page quality
And combined, these create something I reference as the SERP inclusion value.
This is commonly the reason why webpages fall into the “Discovered – currently not indexed” category within Google Search Console’s coverage report.
In the QRGs, Google makes this statement:
Remember that if a page lacks a beneficial purpose, it should always be rated Lowest Page Quality regardless of the page’s Needs Met rating or how well-designed the page may be.
What does this mean? That a page can target the right keywords and tick the right boxes. But if it’s generally repetitive to other content and lacks additional value, then Google may choose not to index it.
This is where we come across Google’s quality threshold, a concept for whether a page meets the necessary “quality” to be indexed.
A key part of how this quality threshold works is that it’s almost real-time and fluid.
Google’s Gary Illyes confirmed this on Twitter, where a URL may become indexed when first found and then dropped when new (better) URLs are found or even given a temporary “freshness” boost from manual submission in GSC.
Working out whether you have an issue
The first thing to identify is if you’re seeing the number of pages in Google Search Console’s coverage report being moved from included to excluded.
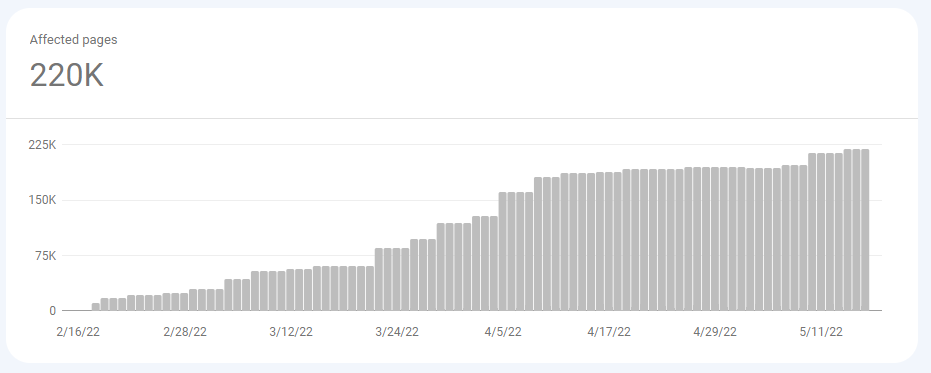
This graph on its own and out of context is enough to cause concern amongst most marketing stakeholders.
But how many of these pages do you care about? How many of these pages drive value?
You’ll be able to identify this through your collective data. You’ll see if traffic and revenue/leads are decreasing in your analytics platform, and you’ll notice in third-party tools if you’re losing overall market visibility and rank.
Once you’ve identified if you are seeing valuable pages dropping out of Google’s index, the next steps are to understand the why and Search Console breaks down excluded into further categories. The main ones you need to be aware of and understand are:
Crawled – currently not indexed
This is something I’ve encountered more with e-commerce and real estate than any other vertical.
In 2021 the number of new business applications registrations in the U.S. broke previous records, and with more businesses competing for users, there is a lot of new content being published – but likely not a lot of new and unique information or perspectives.
Discovered – currently not indexed
When debugging indexing issues, I find this a lot on e-commerce websites or websites that have deployed a considerable programmatic approach to content creation and published a large number of pages at once.
The main reasons pages fall into this category can be down to crawl budget, in that you’ve just published a large amount of content and new URLs and grown the number of crawlable and indexable pages on the site exponentially, and the crawl budget that Google has determined for your site isn’t geared to this many pages.
There’s not a lot you can do to influence this. However, you can help Google through XML sitemaps, HTML sitemaps and good internal linking to pass page rank from important (indexed) pages to these new pages.
The second reason why content may fall into this category is down to quality – and this is common in programmatic content or e-commerce sites with a large number of products and PDPs that are similar or variable products.
Google can identify patterns in URLs, and if it visits a percentage of these pages and finds no value, it can (and sometimes will) make an assumption that the HTML documents with similar URLs will be of equal (low) quality, and it will choose not to crawl them.
A lot of these pages will have been created intentionally with a customer acquisition objective, such as programmatic location pages or comparison pages targeting niche users, but these queries are searched in low frequency, will likely not get many eyes, and the content may not be unique enough versus the other programmatic pages, so Google will not index the low-value proposition content when other alternatives are available.
If this is the case, you will need to assess and determine whether the objectives can be achieved within the project resource and parameters without the excessive pages that are clogging up crawl and not being seen as valuable.
Duplicate content
Duplicate content is one of the more straightforward and is common in e-commerce, publishing and programmatic.
If the main content of the page, which holds the value proposition, is duplicated across other websites or internal pages, then Google won’t invest the resource in indexing the content.
This also ties into the value proposition and the concept of beneficial purpose. I’ve encountered numerous examples where large, authoritative websites have had content not indexed because it is the same as other content available – not offering unique perspectives or unique value propositions.
Taking action
For most large websites and decent-sized medium websites, achieving 100% indexing is only going to get harder as Google has to process all existing and new content on the web.
If you find valuable content being deemed below the quality threshold, what actions should you take?
- Improve internal linking from pages that are “high value”: This doesn’t necessarily mean the pages with the most backlinks, but those pages that rank for a large number of keywords and have good visibility can pass positive signals through descriptive anchors to other pages.
- Prune low-quality, low-value content. If the pages being excluded from the index are low value and not driving any value (e.g., pageviews, conversions), they should be pruned. Having them live is just wasting Google’s crawl resource when it chooses to crawl them, and this can affect their assumptions of quality based on URL pattern matching and perceived inventory.
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
googletag.cmd.push(function() { googletag.display(‘div-gpt-ad-3191538-7’); });
Original Source: Why 100% indexing isn’t possible, and why that’s OK